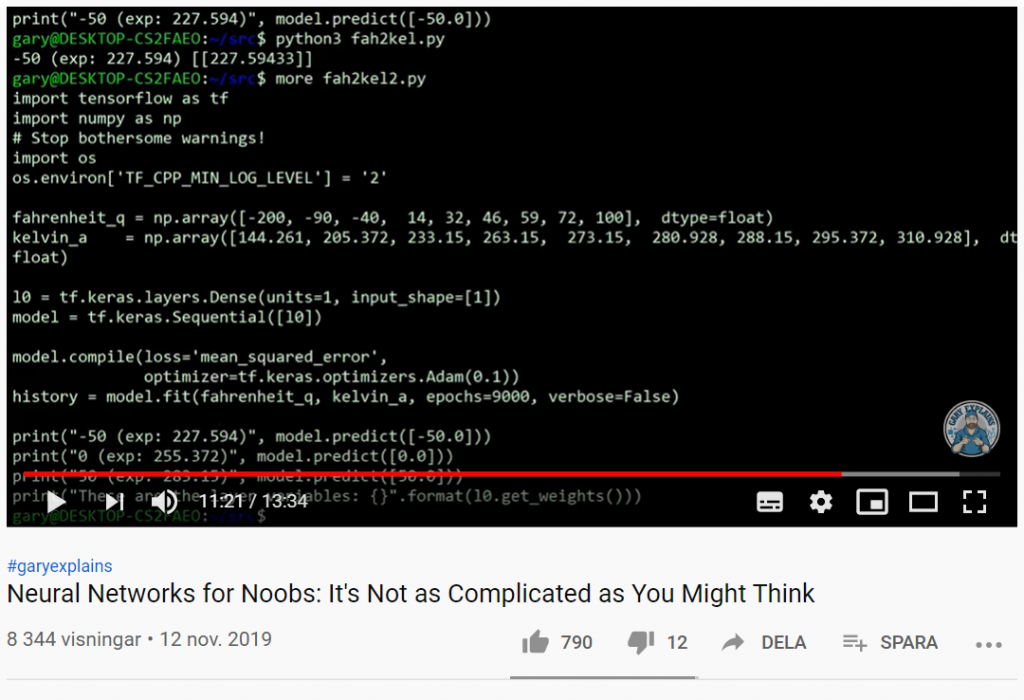
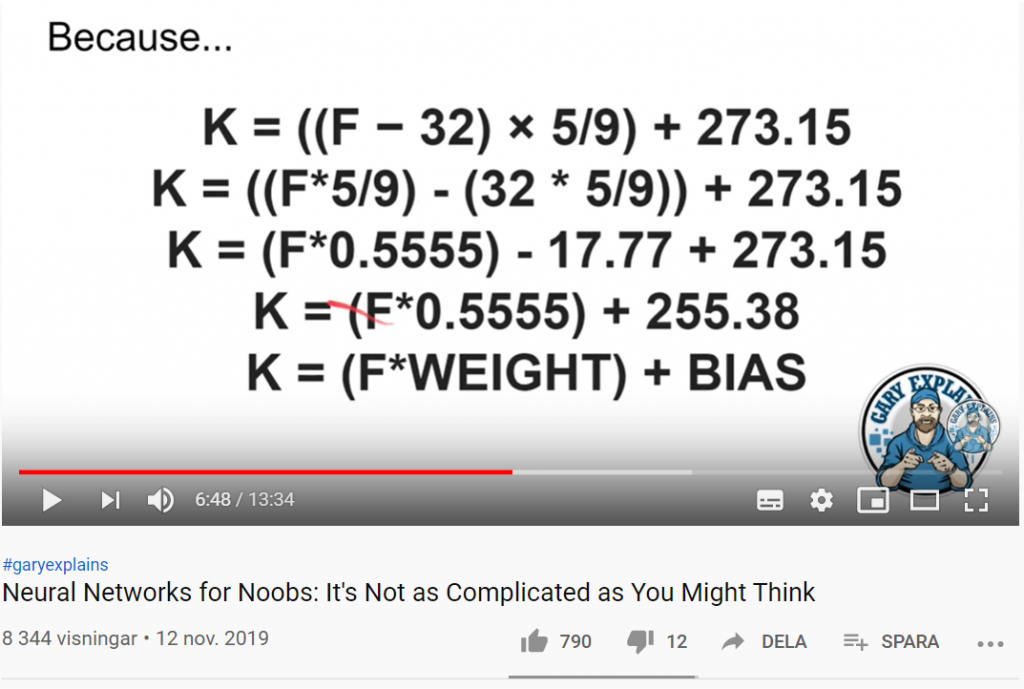Det verkar som om allt drivs av AI nuförtiden. Det handlar dock sällan om speciellt intelligenta system, eller riktig Artificiell Intelligens. AI används mest som en marknadsföringsterm, för det som oftast är maskininlärning (Machine Learning – ML) och tekniker som Neural Networks (NN). Dessa termer kan verka lite skrämmande och svåra, men de är faktiskt inte så komplexa som du kanske tror.
I följande filmklipp ges en enkel och tydlig förklaring till vad neurala nätverk och maskininlärning är, hur det fungerar och vad vi kan använda det till.
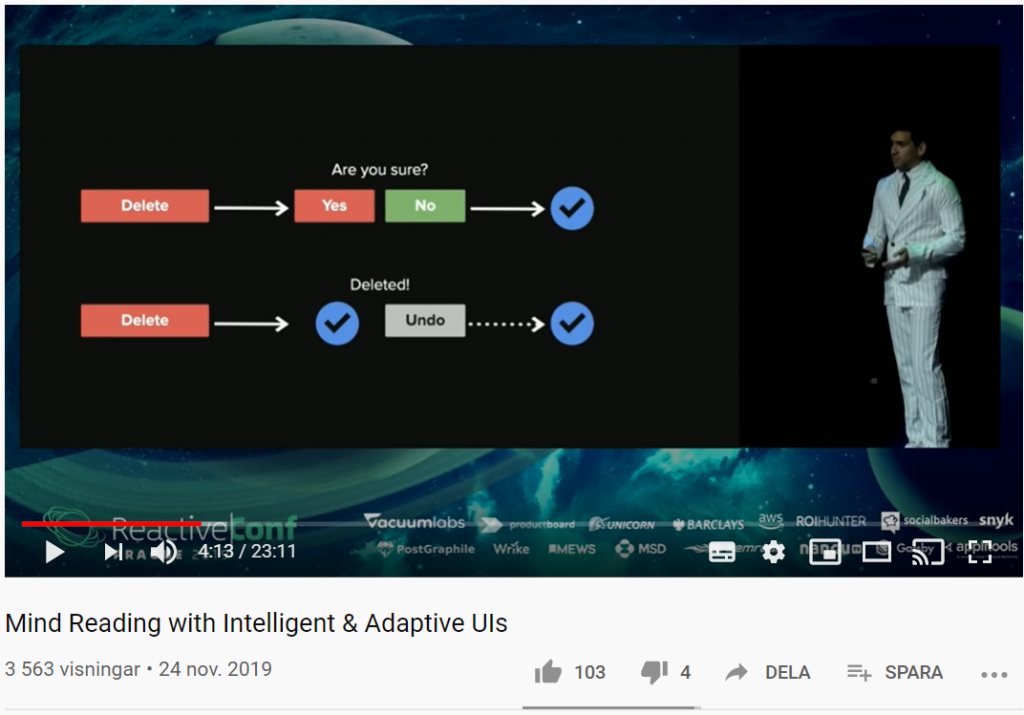
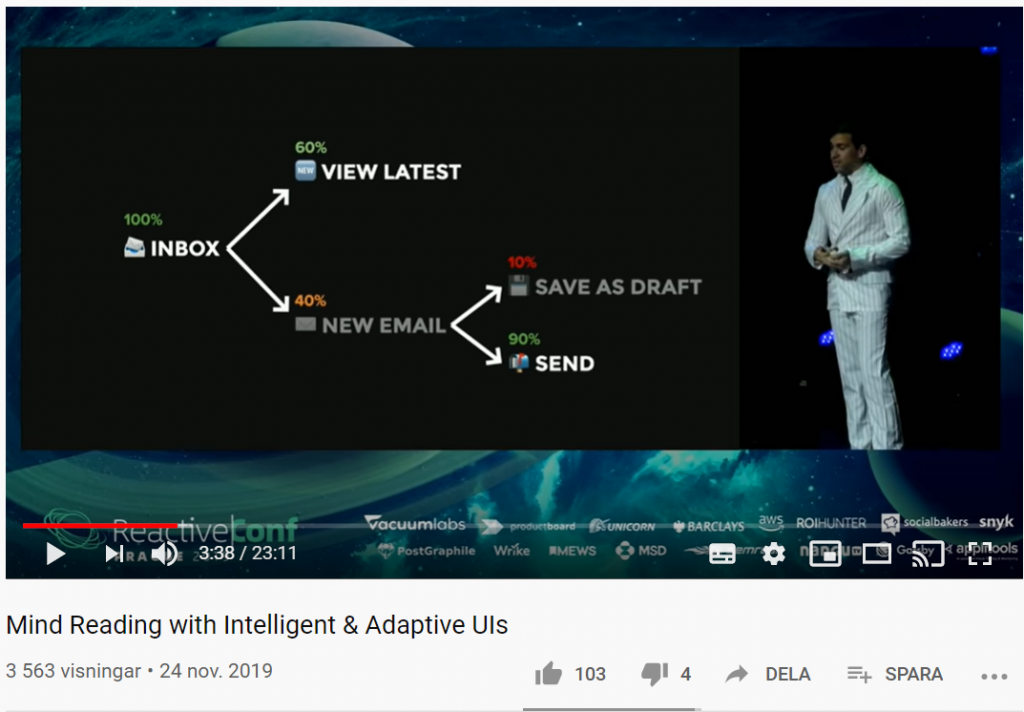
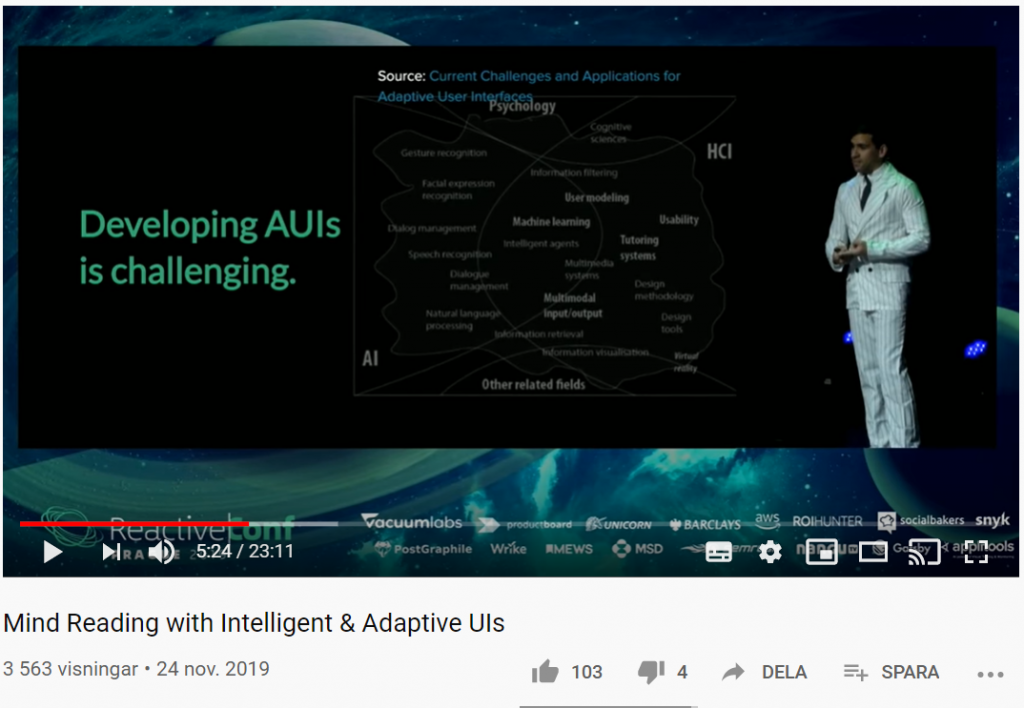
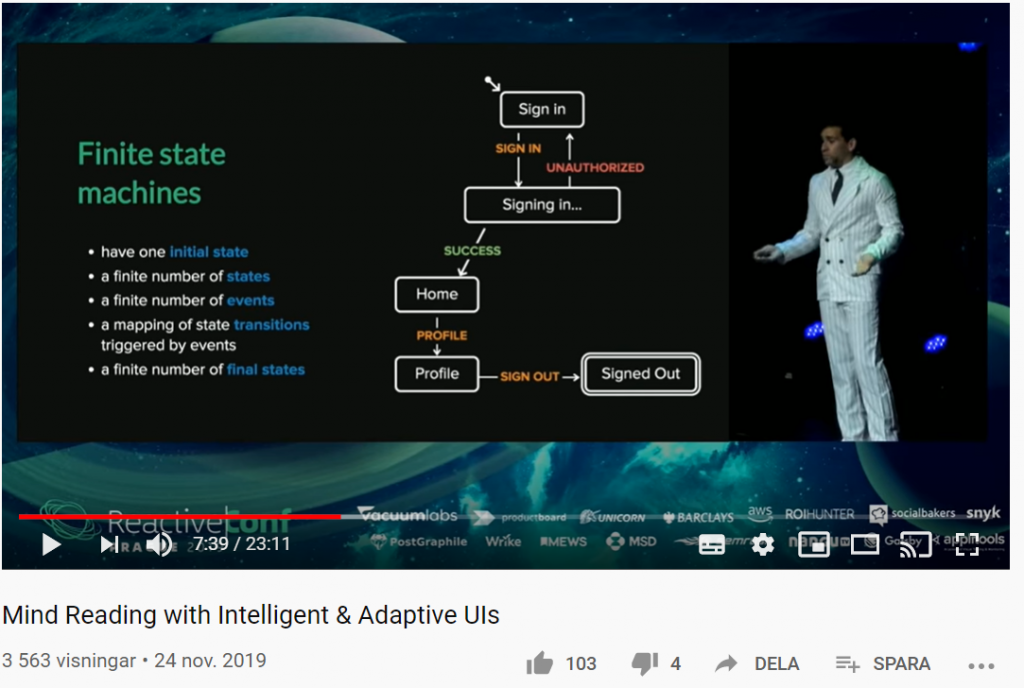
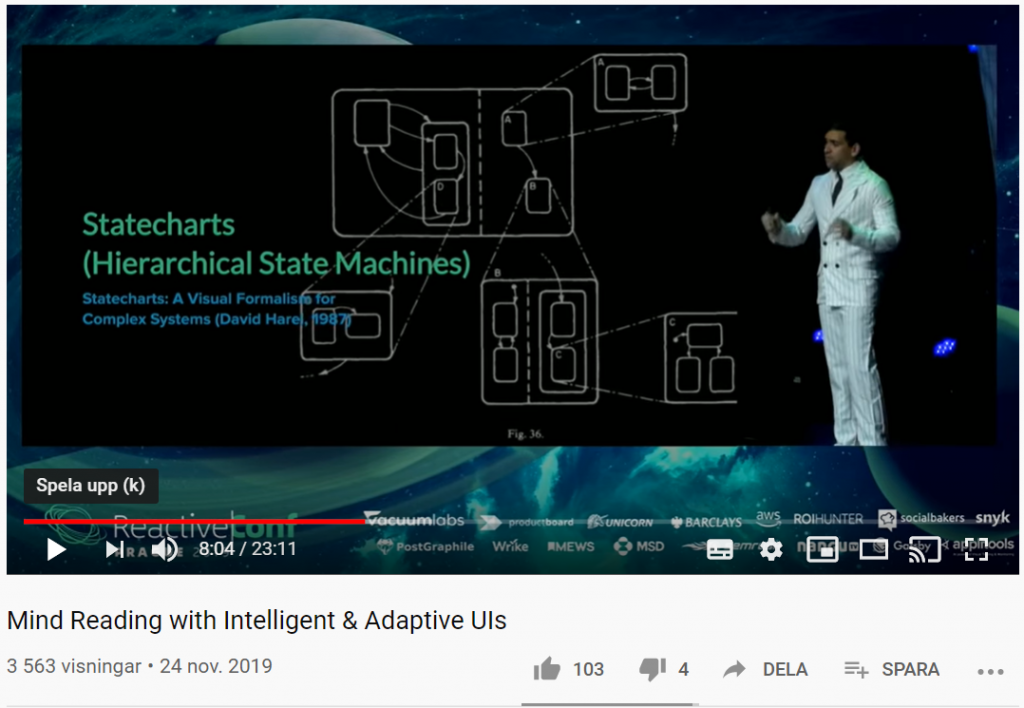
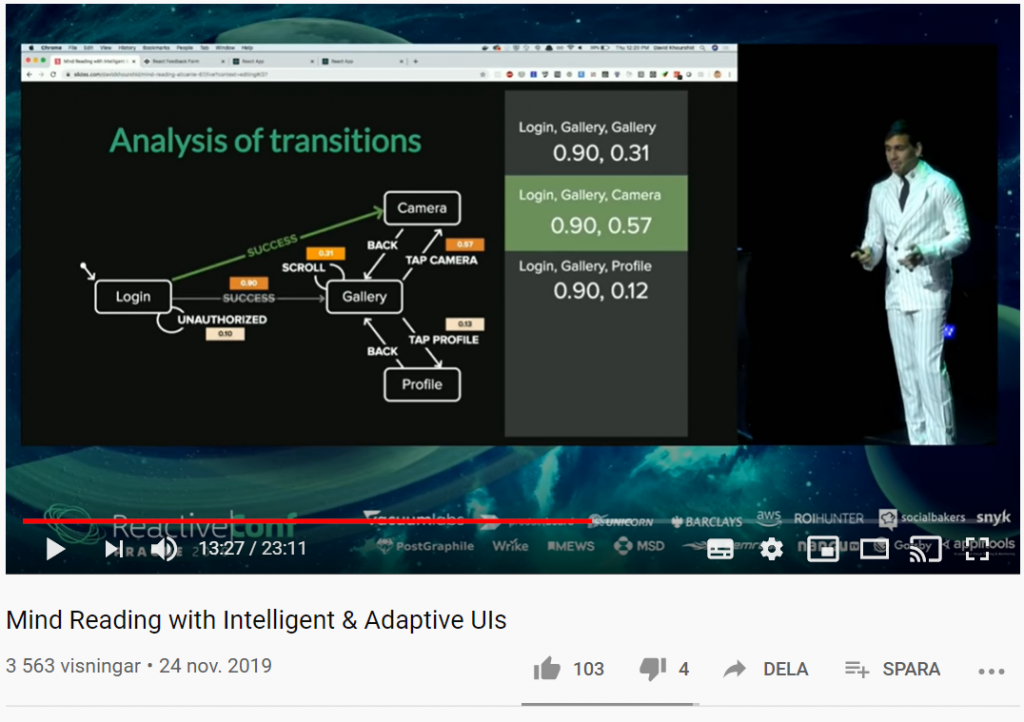
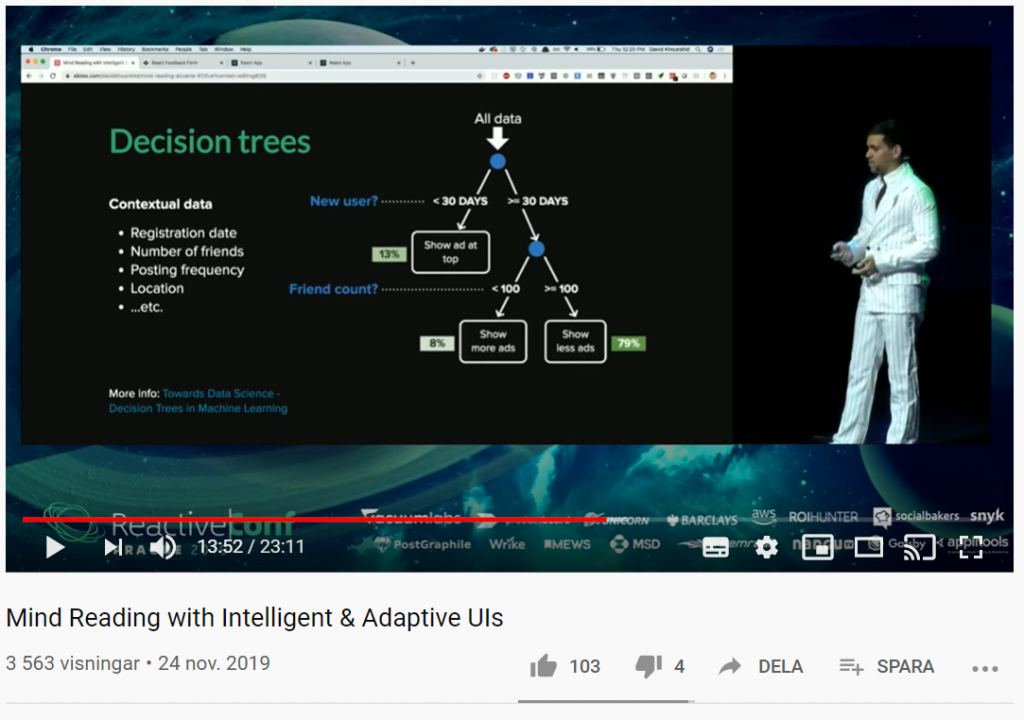
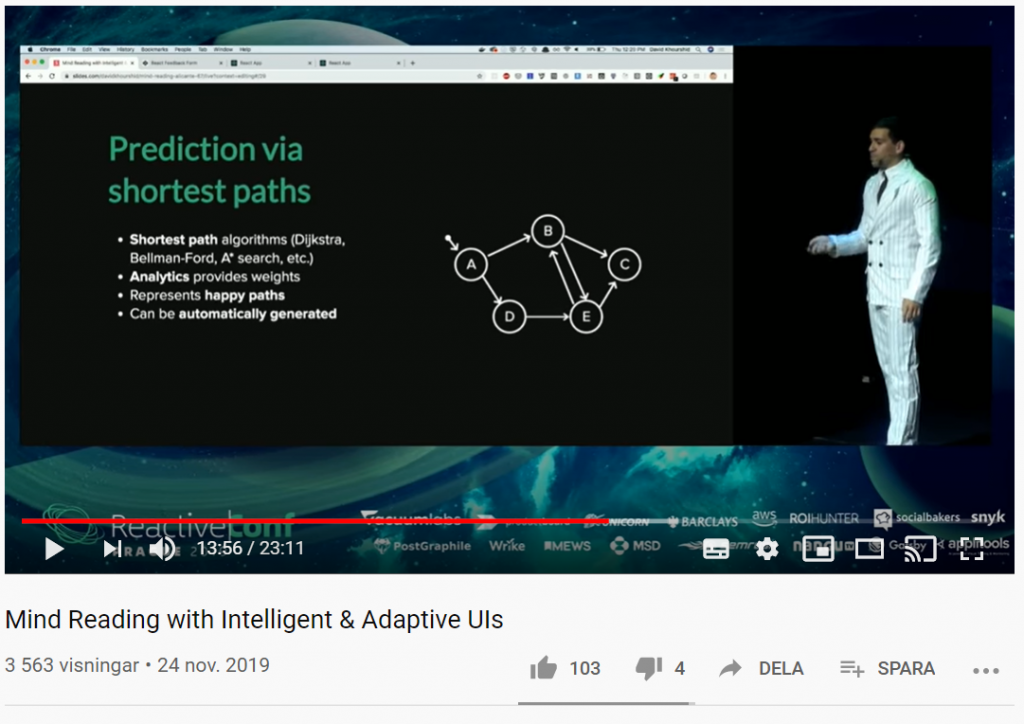
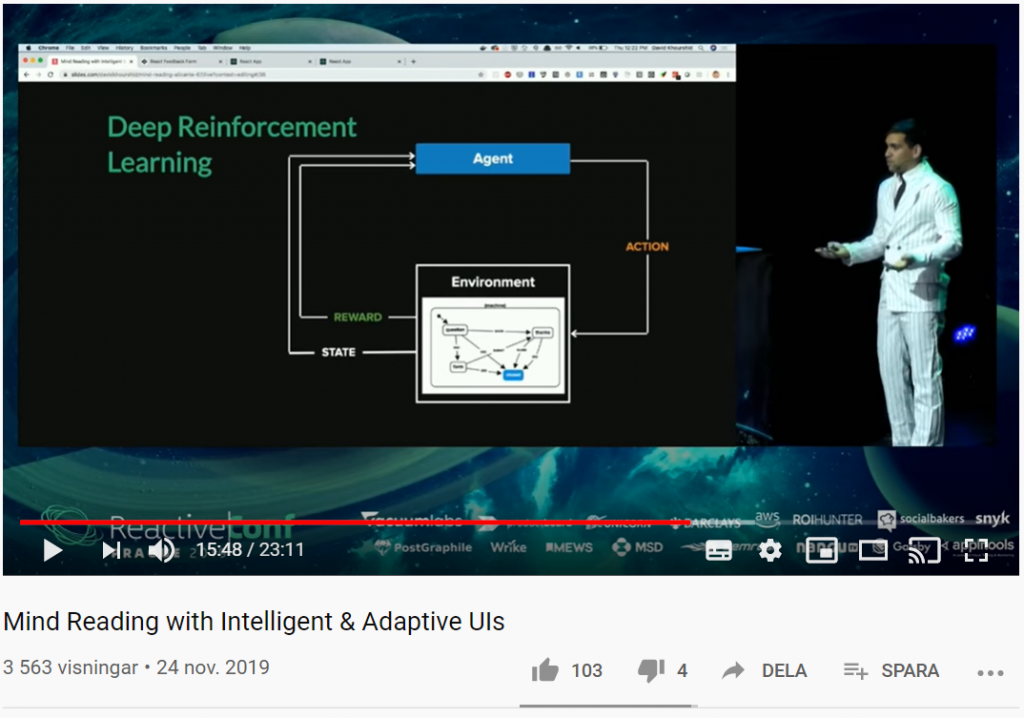
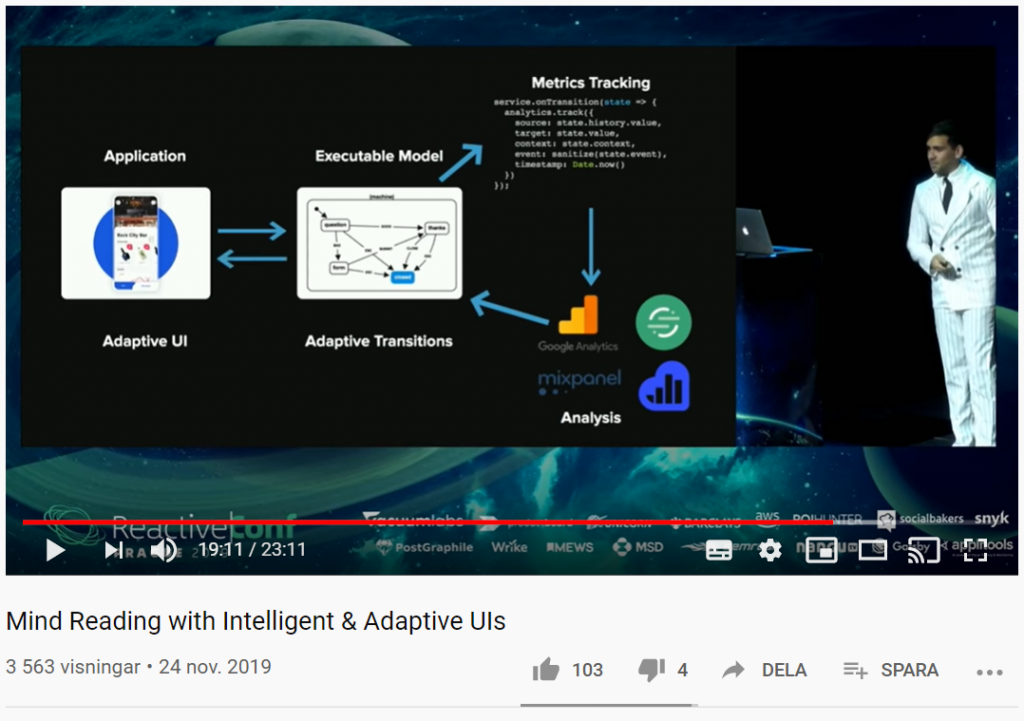
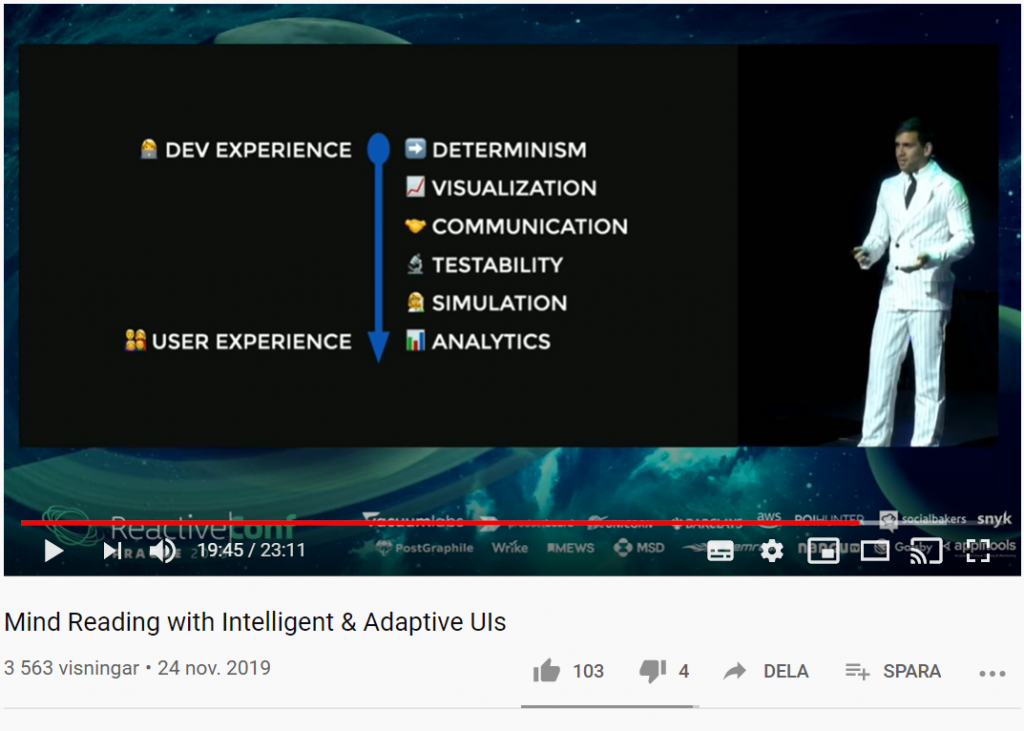
Vad händer om du kan förutsäga användarnas beteende med smarta användargränssnitt? Med sannolikhetsstyrda statecharts, beslutsträd (decision trees), förstärkt inlärning (reinforcement learning) och mer, kan UI:s (User Interfaces) utvecklas på ett sådant sätt att de automatiskt anpassar sig till användarens beteende.
I filmklippet nedan kommer du få se hur du kan skapa anpassningsbara och intelligenta användargränssnitt som lär sig hur individuella användare använder dina appar och anpassar gränssnittet och funktionerna just för dem i realtid.
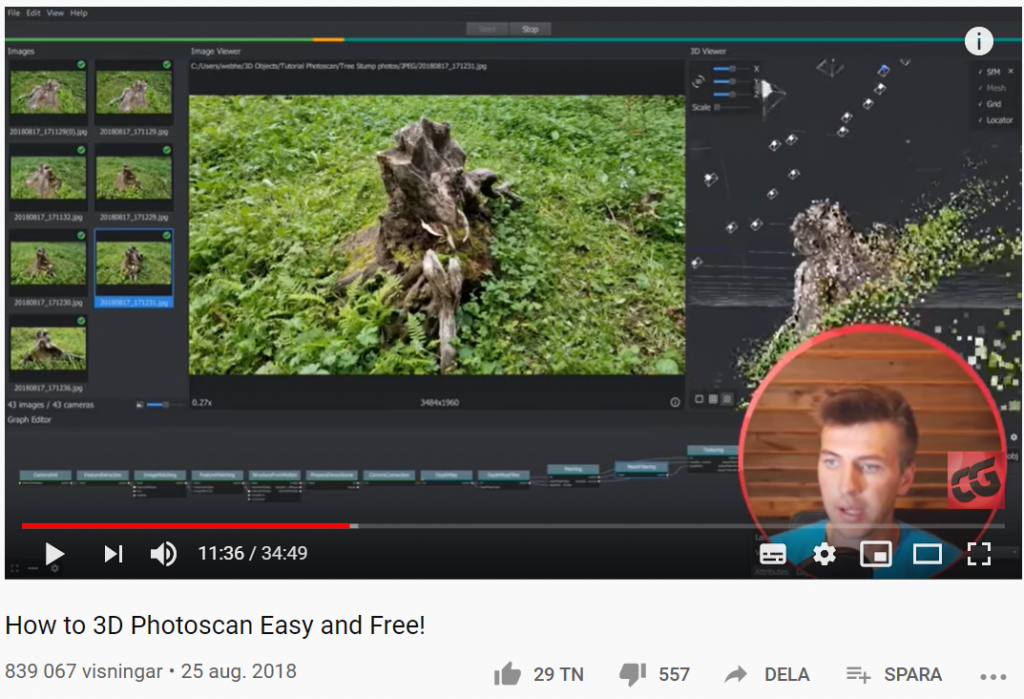
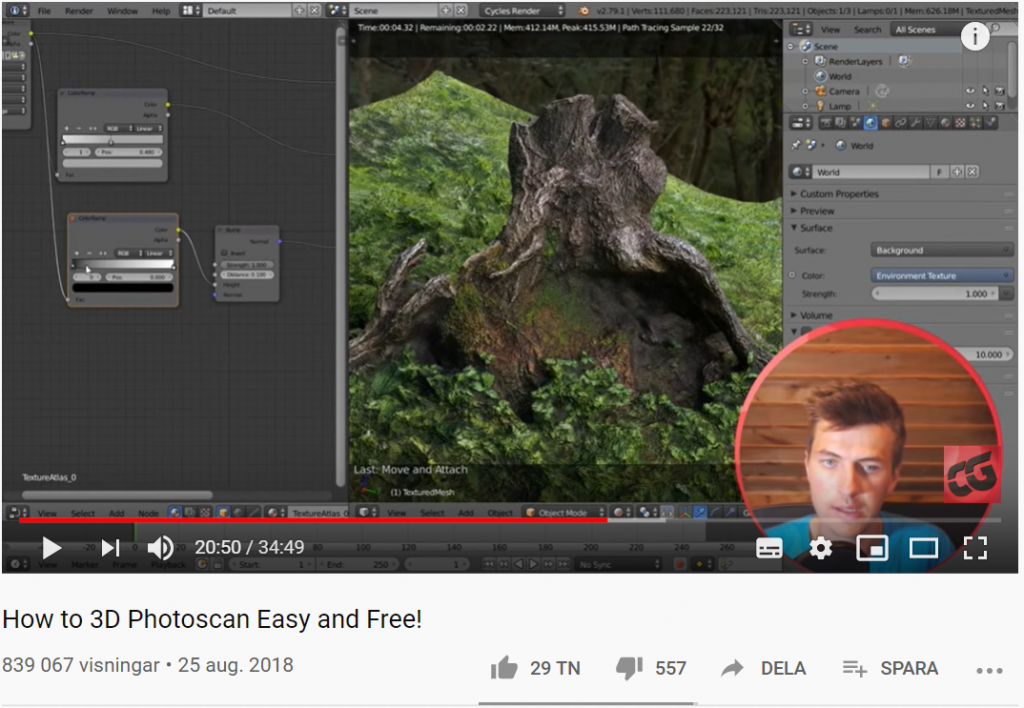
Lär dig hur du 3D-scannar genom att ta mängder av foton med din mobilkamera, importera bilderna i programvaran Meshroom (a free open-source 3D Reconstruction Photogrammetry Software based on the AliceVision framework), och sedan justera, ljussätta och rendera 3D-modellen i Blender för att skapa en fotorealistisk 3D-modell av det du fotograferat av.
00:04 The second half of the last century was completely defined by a technological revolution: the software revolution. The ability to program electrons on a material called silicon made possible technologies, companies and industries that were at one point unimaginable to many of us, but which have now fundamentally changed the way the world works. The first half of this century, though, is going to be transformed by a new software revolution: the living software revolution. And this will be powered by the ability to program biochemistry on a material called biology. And doing so will enable us to harness the properties of biology to generate new kinds of therapies, to repair damaged tissue, to reprogram faulty cells or even build programmable operating systems out of biochemistry. If we can realize this — and we do need to realize it — its impact will be so enormous that it will make the first software revolution pale in comparison.
01:11
And that’s because living software would transform the entirety of medicine, agriculture and energy, and these are sectors that dwarf those dominated by IT. Imagine programmable plants that fix nitrogen more effectively or resist emerging fungal pathogens, or even programming crops to be perennial rather than annual so you could double your crop yields each year. That would transform agriculture and how we’ll keep our growing and global population fed. Or imagine programmable immunity, designing and harnessing molecular devices that guide your immune system to detect, eradicate or even prevent disease. This would transform medicine and how we’ll keep our growing and aging population healthy.
01:59
We already have many of the tools that will make living software a reality. We can precisely edit genes with CRISPR. We can rewrite the genetic code one base at a time. We can even build functioning synthetic circuits out of DNA. But figuring out how and when to wield these tools is still a process of trial and error. It needs deep expertise, years of specialization. And experimental protocols are difficult to discover and all too often, difficult to reproduce. And, you know, we have a tendency in biology to focus a lot on the parts, but we all know that something like flying wouldn’t be understood by only studying feathers. So programming biology is not yet as simple as programming your computer. And then to make matters worse, living systems largely bear no resemblance to the engineered systems that you and I program every day. In contrast to engineered systems, living systems self-generate, they self-organize, they operate at molecular scales. And these molecular-level interactions lead generally to robust macro-scale output. They can even self-repair.
03:07
Consider, for example, the humble household plant, like that one sat on your mantelpiece at home that you keep forgetting to water. Every day, despite your neglect, that plant has to wake up and figure out how to allocate its resources. Will it grow, photosynthesize, produce seeds, or flower? And that’s a decision that has to be made at the level of the whole organism. But a plant doesn’t have a brain to figure all of that out. It has to make do with the cells on its leaves. They have to respond to the environment and make the decisions that affect the whole plant. So somehow there must be a program running inside these cells, a program that responds to input signals and cues and shapes what that cell will do. And then those programs must operate in a distributed way across individual cells, so that they can coordinate and that plant can grow and flourish.
03:59
If we could understand these biological programs, if we could understand biological computation, it would transform our ability to understand how and why cells do what they do. Because, if we understood these programs, we could debug them when things go wrong. Or we could learn from them how to design the kind of synthetic circuits that truly exploit the computational power of biochemistry.
04:25
My passion about this idea led me to a career in research at the interface of maths, computer science and biology. And in my work, I focus on the concept of biology as computation. And that means asking what do cells compute, and how can we uncover these biological programs? And I started to ask these questions together with some brilliant collaborators at Microsoft Research and the University of Cambridge, where together we wanted to understand the biological program running inside a unique type of cell: an embryonic stem cell. These cells are unique because they’re totally naïve. They can become anything they want: a brain cell, a heart cell, a bone cell, a lung cell, any adult cell type. This naïvety, it sets them apart, but it also ignited the imagination of the scientific community, who realized, if we could tap into that potential, we would have a powerful tool for medicine. If we could figure out how these cells make the decision to become one cell type or another, we might be able to harness them to generate cells that we need to repair diseased or damaged tissue. But realizing that vision is not without its challenges, not least because these particular cells, they emerge just six days after conception. And then within a day or so, they’re gone. They have set off down the different paths that form all the structures and organs of your adult body.
05:51
But it turns out that cell fates are a lot more plastic than we might have imagined. About 13 years ago, some scientists showed something truly revolutionary. By inserting just a handful of genes into an adult cell, like one of your skin cells, you can transform that cell back to the naïve state. And it’s a process that’s actually known as ”reprogramming,” and it allows us to imagine a kind of stem cell utopia, the ability to take a sample of a patient’s own cells, transform them back to the naïve state and use those cells to make whatever that patient might need, whether it’s brain cells or heart cells.
06:30
But over the last decade or so, figuring out how to change cell fate, it’s still a process of trial and error. Even in cases where we’ve uncovered successful experimental protocols, they’re still inefficient, and we lack a fundamental understanding of how and why they work. If you figured out how to change a stem cell into a heart cell, that hasn’t got any way of telling you how to change a stem cell into a brain cell. So we wanted to understand the biological program running inside an embryonic stem cell, and understanding the computation performed by a living system starts with asking a devastatingly simple question: What is it that system actually has to do?
07:13
Now, computer science actually has a set of strategies for dealing with what it is the software and hardware are meant to do. When you write a program, you code a piece of software, you want that software to run correctly. You want performance, functionality. You want to prevent bugs. They can cost you a lot. So when a developer writes a program, they could write down a set of specifications. These are what your program should do. Maybe it should compare the size of two numbers or order numbers by increasing size. Technology exists that allows us automatically to check whether our specifications are satisfied, whether that program does what it should do. And so our idea was that in the same way, experimental observations, things we measure in the lab, they correspond to specifications of what the biological program should do.
08:02
So we just needed to figure out a way to encode this new type of specification. So let’s say you’ve been busy in the lab and you’ve been measuring your genes and you’ve found that if Gene A is active, then Gene B or Gene C seems to be active. We can write that observation down as a mathematical expression if we can use the language of logic: If A, then B or C. Now, this is a very simple example, OK. It’s just to illustrate the point. We can encode truly rich expressions that actually capture the behavior of multiple genes or proteins over time across multiple different experiments. And so by translating our observations into mathematical expression in this way, it becomes possible to test whether or not those observations can emerge from a program of genetic interactions.
08:55
And we developed a tool to do just this. We were able to use this tool to encode observations as mathematical expressions, and then that tool would allow us to uncover the genetic program that could explain them all. And we then apply this approach to uncover the genetic program running inside embryonic stem cells to see if we could understand how to induce that naïve state. And this tool was actually built on a solver that’s deployed routinely around the world for conventional software verification. So we started with a set of nearly 50 different specifications that we generated from experimental observations of embryonic stem cells. And by encoding these observations in this tool, we were able to uncover the first molecular program that could explain all of them.
09:43
Now, that’s kind of a feat in and of itself, right? Being able to reconcile all of these different observations is not the kind of thing you can do on the back of an envelope, even if you have a really big envelope. Because we’ve got this kind of understanding, we could go one step further. We could use this program to predict what this cell might do in conditions we hadn’t yet tested. We could probe the program in silico.
10:08
And so we did just that: we generated predictions that we tested in the lab, and we found that this program was highly predictive. It told us how we could accelerate progress back to the naïve state quickly and efficiently. It told us which genes to target to do that, which genes might even hinder that process. We even found the program predicted the order in which genes would switch on. So this approach really allowed us to uncover the dynamics of what the cells are doing.
10:39
What we’ve developed, it’s not a method that’s specific to stem cell biology. Rather, it allows us to make sense of the computation being carried out by the cell in the context of genetic interactions. So really, it’s just one building block. The field urgently needs to develop new approaches to understand biological computation more broadly and at different levels, from DNA right through to the flow of information between cells. Only this kind of transformative understanding will enable us to harness biology in ways that are predictable and reliable.
11:12
But to program biology, we will also need to develop the kinds of tools and languages that allow both experimentalists and computational scientists to design biological function and have those designs compile down to the machine code of the cell, its biochemistry, so that we could then build those structures. Now, that’s something akin to a living software compiler, and I’m proud to be part of a team at Microsoft that’s working to develop one. Though to say it’s a grand challenge is kind of an understatement, but if it’s realized, it would be the final bridge between software and wetware.
11:48
More broadly, though, programming biology is only going to be possible if we can transform the field into being truly interdisciplinary. It needs us to bridge the physical and the life sciences, and scientists from each of these disciplines need to be able to work together with common languages and to have shared scientific questions.
12:08
In the long term, it’s worth remembering that many of the giant software companies and the technology that you and I work with every day could hardly have been imagined at the time we first started programming on silicon microchips. And if we start now to think about the potential for technology enabled by computational biology, we’ll see some of the steps that we need to take along the way to make that a reality. Now, there is the sobering thought that this kind of technology could be open to misuse. If we’re willing to talk about the potential for programming immune cells, we should also be thinking about the potential of bacteria engineered to evade them. There might be people willing to do that. Now, one reassuring thought in this is that — well, less so for the scientists — is that biology is a fragile thing to work with. So programming biology is not going to be something you’ll be doing in your garden shed. But because we’re at the outset of this, we can move forward with our eyes wide open. We can ask the difficult questions up front, we can put in place the necessary safeguards and, as part of that, we’ll have to think about our ethics. We’ll have to think about putting bounds on the implementation of biological function. So as part of this, research in bioethics will have to be a priority. It can’t be relegated to second place in the excitement of scientific innovation.
13:26
But the ultimate prize, the ultimate destination on this journey, would be breakthrough applications and breakthrough industries in areas from agriculture and medicine to energy and materials and even computing itself. Imagine, one day we could be powering the planet sustainably on the ultimate green energy if we could mimic something that plants figured out millennia ago: how to harness the sun’s energy with an efficiency that is unparalleled by our current solar cells. If we understood that program of quantum interactions that allow plants to absorb sunlight so efficiently, we might be able to translate that into building synthetic DNA circuits that offer the material for better solar cells. There are teams and scientists working on the fundamentals of this right now, so perhaps if it got the right attention and the right investment, it could be realized in 10 or 15 years.
14:18
So we are at the beginning of a technological revolution. Understanding this ancient type of biological computation is the critical first step. And if we can realize this, we would enter in the era of an operating system that runs living software.
Cura är ett open-source slicer-program. Det är ursprungligen utvecklat av företaget Ultimaker som en slicer till deras 3D-skrivare, men fungerar lika bra till nästan alla andra 3D-skrivare på marknaden. Det är ett av de mest populära programmen för detta ändamål.
För att skriva ut saker i en en 3D-skrivare behövs ett så kallat slicer-program. Det är ett program som gör om en STL-fil till G-code som 3D-skrivaren kan tolka. Slicern skivar upp 3D-modellen i olika lager där G-coden bestämmer var det ska läggas ut filament och hur. Här är ett antal parametrar man kan justera i inställningarna för sin 3D-utskrift:
Layer height: Höjden på varje lager i utskriften
Wall thickness: Tjockleken på väggarna i utskriften
Top/bottom thickness: Tjockleken på “tak” och “golv” i utskriften
Infill density: Hur mycket av insidan ska täckas upp med material?
Printing temperature: Temperatur på munstycke – beror på vilket material vi väljer
Build plate temperature: Temperatur på byggplatta – beror på vilket material vi väljer
Travel speed: Hur fort munstycket rör sig när det inte extruderar plast
Enable print cooling: Om vi vill kyla plasten med “part cooling fan” när det kommer ut
Build plate adhesion: Olika metoder för att få bättre fäste vid byggplatta
Enable supports: Om det automatiskt ska genereras stödstrukturer
Support placement: Vart stödstrukturer ska genereras
Support density: Hur mycket stödstrukturer ska genereras
Support overhang angle: Vart stödstrukturer ska genereras
Print speed: Utskriftshastighet – hur fort munstycket rör sig när det extruderar plast
I nedanstående filmklipp visar Chuck dig tre Cura Slicer-inställningstrick för nybörjare som han använder på sina ENDER 3 och CR-10 Mini hela tiden. Dessa Cura-tricks är särskilt användbara för alla som precis kommit igång med 3D-printing.
Om ett 3D-objekt du vill skriva ut har delar med överhäng behöver du använda supportmaterial eller s k stödstrukturer. Det finns olika sätt att lägga till stödstrukturer till ett en 3D-modell. Hur du ställer in Cura Tree Supports (trädstöd) och Simple Support och vilka inställningar du kan göra hittar du i nedanstånde avsnitt av Filament Friday med Chuck. Han använder en enkel testutskrift för att se vilket Cura-stöd som fungerar bäst och varför. Han visar hur enkla de är att ta bort och hur bra utskriften ser ut när du är klar.
Med en plugin till Cura går det att skapa mer precisa manuella stödstrukturer bara just där du vill ha dem, så att du kan spara plast och snabba upp utskrifterna jämfört mot att använda de automatiska verktygen.
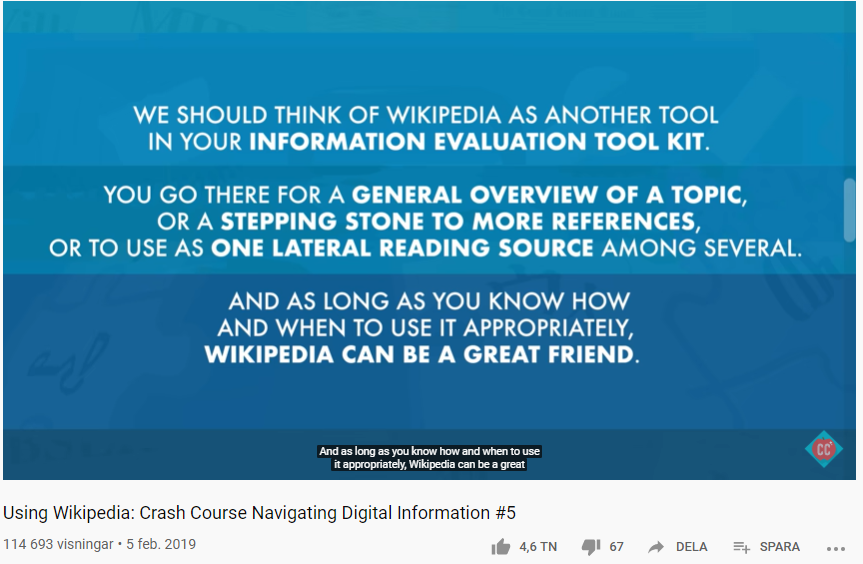
Här är en crash course i att använda Wikipedia för att söka, hitta och navigera rätt bland digital information på webben. Wikipedia är en källa som ofta nedvärderas av lärare och twittertroll som en opålitlig källa. Och ja, det finns ibland stora fel och utelämnanden, men Wikipedia är också Internets största allmänna referensverk och som sådant ett otroligt kraftfullt verktyg. I följande filmklipp får du tips på hur du kan använda Wikipedia för ett gott syfte – för att hjälpa dig att få ett fågelperspektiv över ett visst innehåll, bättre kunna utvärdera information med lateral läsning och hitta pålitliga primära källor.
Lateral läsning är en lässtrategi som lämpar sig betydligt bättre för informationssökning på webben än traditionell vertikal läsning som man gör i tryckta böcker eller papperstidningar där man läser varje sida uppifrån och ner. Det handlar istället om att hoppa horisontellt mellan olika webbläsarflikar och läsa om en viss sak på flera olika sidor för att snabbt få en överblick från flera olika perspektiv. Risken med att läsa vertikalt på enskilda webbsidor och bara leta efter tecken på om källan verkar seriös och trovärdig på den aktuella webbsidan kan sammanfattas i följande citat: ”Reading that way gives misinformation and disinformation more power. It allows people to hijack your consciousness, and it also makes you part of the problem.”
Känner du dig ibland trött under möten eller i skolan? Har du ibland huvudvärk efter jobbet eller skolan? Vill du ändra på det? Då kan det vara intressant för dig att mäta skadliga gaser i luften i din arbetsmiljö, vilka kan resultera i både trötthet och huvudvärk.
I filmklippet nedan används en ESP32 och två ESP8266 med sensorer för att bygga ett system som mäter luftkvaliteten. Sensorerna som används är: Winsen MH-Z19, Sensirion SGP30 och SCD30. I denna video:
Fokusera på inomhusklimat
Fokusera på gaser där den främsta källan är människor
CO2:s påverkan på luftkvaliteten inomhus
Se förhållandet mellan CO2-sensorer och global uppvärmning
Använd ett annat sätt för att bedöma inomhusluften: VOC eller eCO2
Och vi kommer att bygga sensorer för att överföra värden till Grafana
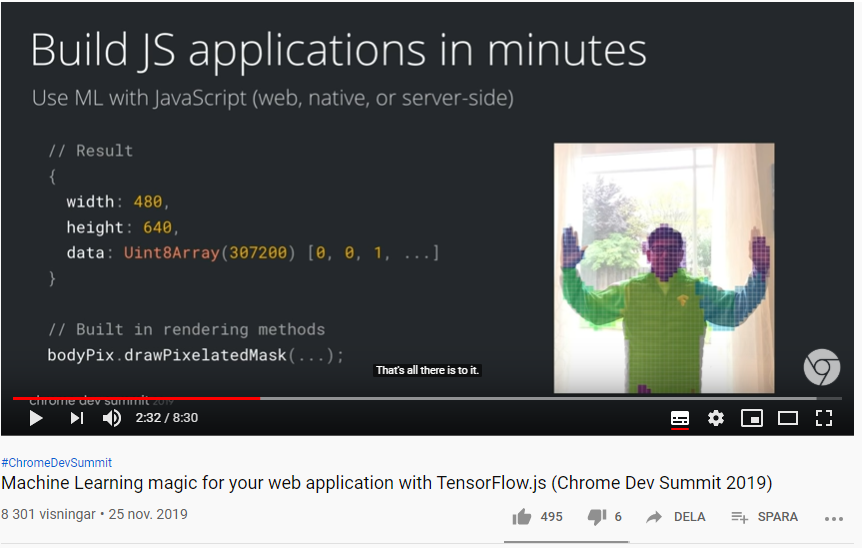
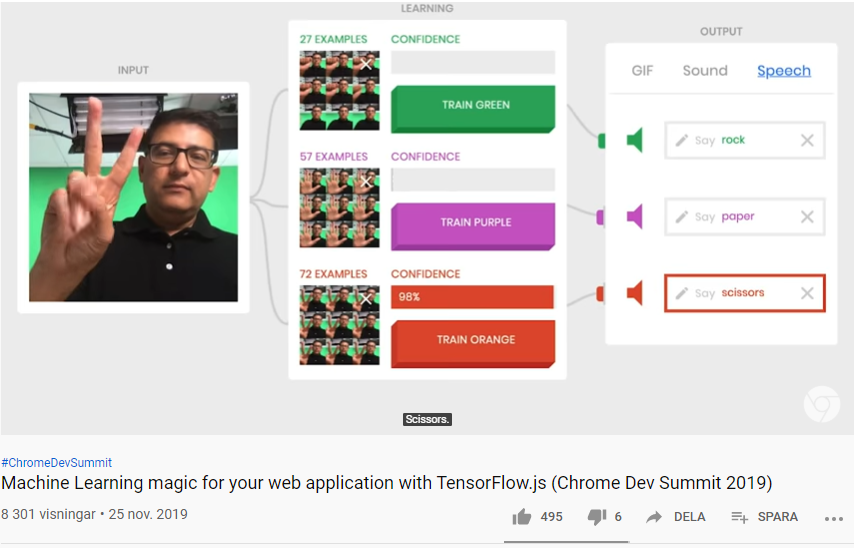
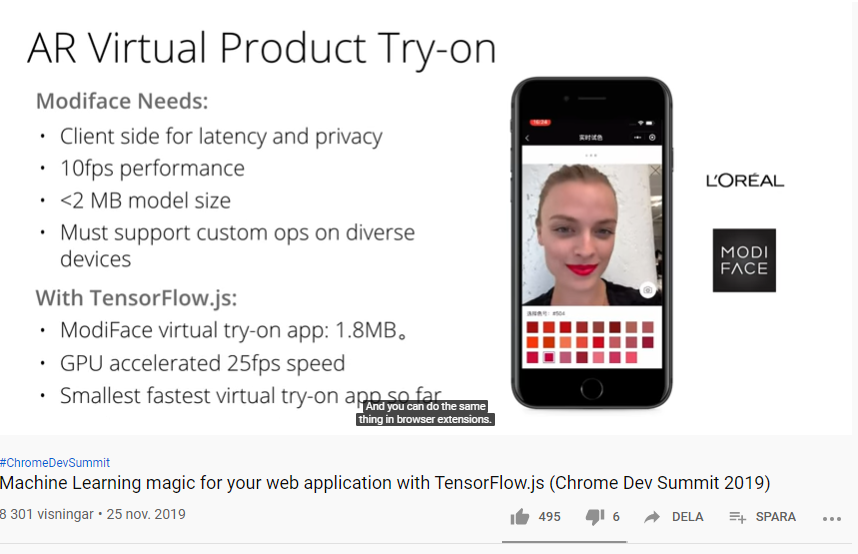
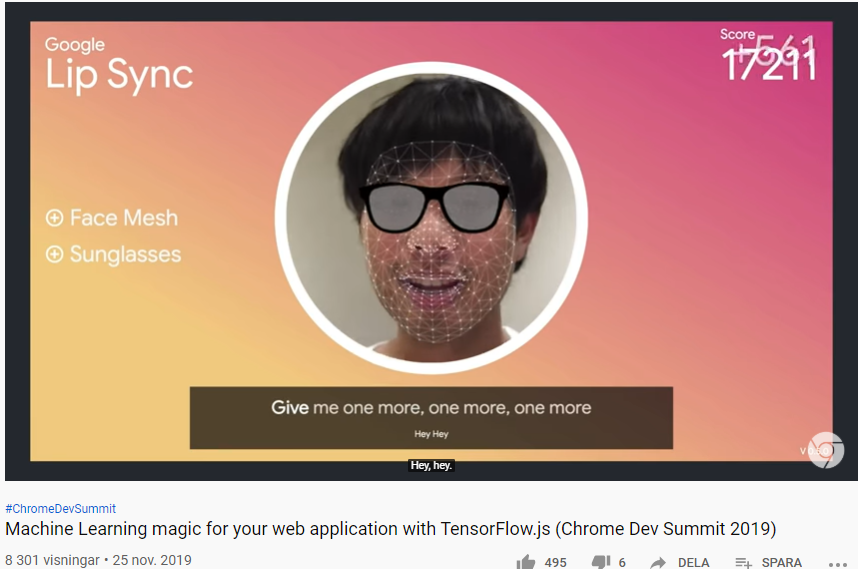
Med TensorFlow.js kan du snabbt och enkelt skapa webbapplikationer som använder Artificiell Intelligens (AI) och Machine Learning (ML) med ett fåtal rader JavaScript-kod. Det finns en hel del färdigbyggda och förtränade ML-modeller med JavaScript API:er som du kan använda direkt för tillämpningar som t ex: Image Classification Image Segmentation Object Detection Pose Detection Speech Commands Text Classifications Augmented Reality Gesture-based interaction Speech recognition Accessible web apps Sentiment analysis, abuse detection Conversational AI Web page optimization m.m.